Reducing container pull time with eStargz lazy-pulling


The KubeCon + CloudNativeCon North America is one of the biggest events around Kubernetes and the cloud native community. This year, despite the large variety of sessions on its schedule, there's been one session that has brought my interest:
Today I'll talk about the recent status of lazy pulling of containers (eStargz, nydus) with Tao Peng at #KubeCon.
— Kohei Tokunaga (@TokunagaKohei) October 14, 2021
I'll attend virtually so meet on the event platform or on cncf slack (#2-kubecon-runtimes)!https://t.co/jdVhDtHsre
Pull operations take time
Just right before running a container, a pull operation occurs to download the container image from a registry (assuming it is not already present in the node's cache, of course). The time the pull operation takes depends on several factors, such as the image size and the network connection of the node.
Pulling packages accounts for 76% of container start time, but only 6.4% of that data is read [Harter et al. 2016]
Therefore, the larger the container image, the longer it will take to start the container. Although reducing the image size following Dockerfile best practices is very convenient, e.g. using multi-stage builds, there are situations where the image cannot be reduced further, e.g. language runtimes, frameworks or other dependencies that are strictly necessary for a container to run.
For instance, in serverless scenarios using OpenFaaS or KEDA, where we need to spin up containers on-demand to handle user requests, long pull operations due to large image sizes is aggravated. Under such delicate scenarios, reducing the cold start time of the container is very important.
So, if we are given a relatively large container image ( > 1 GB), how can we start the container before all the layers become locally available in the node?
eStargz: Standard-compatible lazy pulling
Lazy pulling means a container can run without waiting for the pull completion of the image and necessary chunks of the image are fetched on-demand.
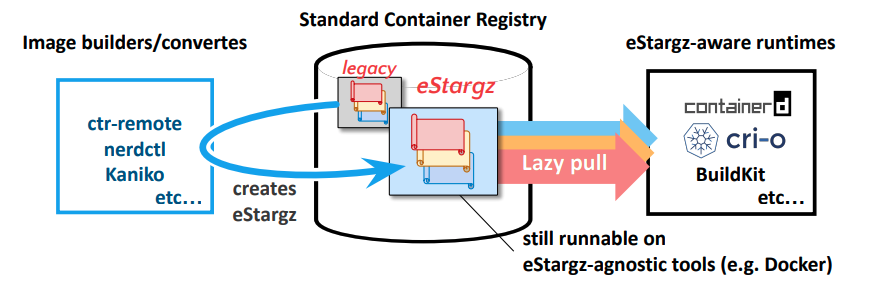
eStargz is a lazily-pullable image format proposed by the Stargz Snapshotter, a non-core subproject of containerd.
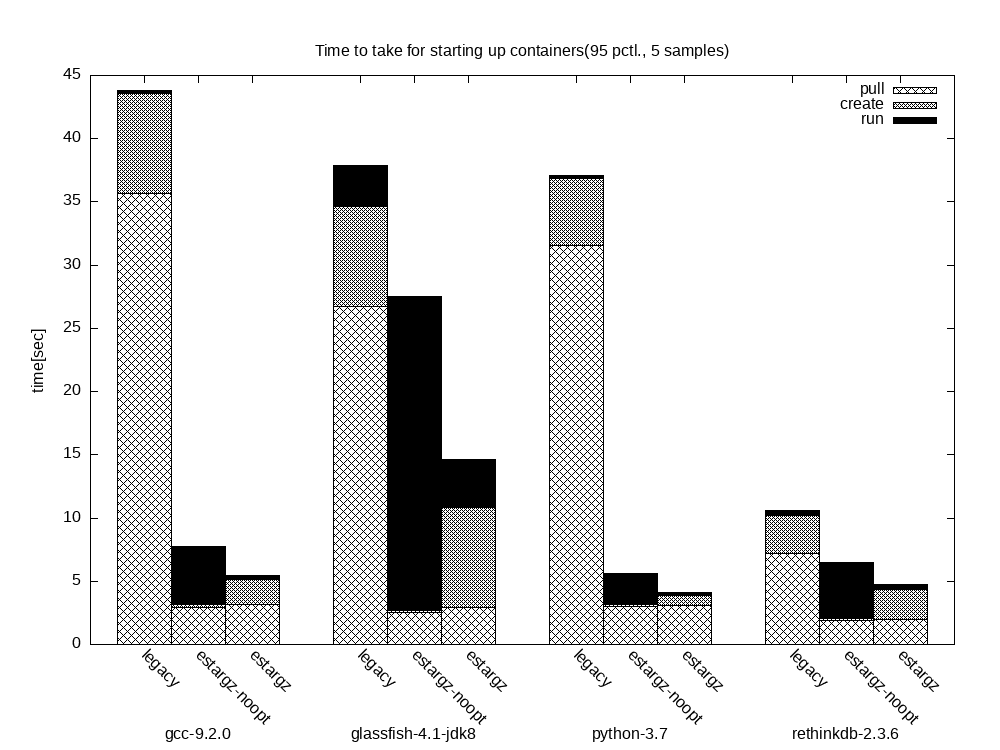
As you can see in the picture above, the overall time it takes for starting up containers is lower in the case of images that are eStargz-optimized. The pull operation portion is smaller given that it is not necessary to download all the layers anymore, while the create and run portions have been increased to a greater or lesser extent. Nonetheless, the overall container startup time is lower.
Furthermore, eStargz is compatible with OCI, meaning that eStargz-agnostic runtimes can pull and run eStargz-optimized images in just the same way as other OCI/Docker images. Furthermore, eStargz images can be pulled from standard registries such as ghcr.io (GitHub container registry) and docker.io, among others.
For instance, BuildKit >= 0.8.0 supports lazy-pulling base images and building eStargz images. Check out the adoption matrix to know what other tools support lazy-pulling, chunk verification, and more.
Trying it out in Kubernetes
For using Stargz Snapshotter on Kubernetes nodes, you need to provide with a specific configuration to containerd as well as run the Stargz Snapshotter daemon on the node.
Ensure you're using containerd v1.4.2 or a more recent version for the node container runtime.
Just for the sake of the demo, I've used KinD to quickly spin up a local Kubernetes cluster and used the prebuilt KinD node image that already comes with the required configuration.
kind create cluster --name stargz-demo --image ghcr.io/stargz-containers/estargz-kind-node:0.7.0Once the Kubernetes cluster is up and running, we can deploy two Pods to the cluster and check how much time the pull operation takes for them:
- A pod that uses a non-optimized image such as
node:13.13. - A pod that uses an eStargz-optimized image such as
ghcr.io/stargz-containers/node:13.13.0-esgz.
If you wish, you can try other pre-converted eStargz images on ghcr.io listed here.
Below it is the Pod spec that corresponds with the non-opt image. It will spin up a node server using the image node:13.13.
apiVersion: v1
kind: Pod
metadata:
name: nodejs
spec:
containers:
- name: nodejs
image: node:13.13
command: ["node"]
args:
- -e
- var http = require('http');
http.createServer(function(req, res) {
res.writeHead(200);
res.end('Hello World!\n');
}).listen(80);
ports:
- containerPort: 80Let's apply the Pod spec to the cluster:
kubectl apply -f pod.ymland watch the events with kubectl describe pod nodejs:
│ Events: │
│ Type Reason Age From Message │
│ ---- ------ ---- ---- ------- │
│ Warning FailedScheduling 38s (x3 over 46s) default-scheduler 0/1 nodes are available: 1 node(s) had taint {node.kubernetes.io/not-ready: }, that the pod didn't │
│ tolerate. │
│ Normal Scheduled 33s default-scheduler Successfully assigned default/nodejs to stargz-demo-control-plane │
│ Normal Pulling 32s kubelet Pulling image "node:13.13" │
│ Normal Pulled 5s kubelet Successfully pulled image "node:13.13" in 26.262296654s │
│ Normal Created 5s kubelet Created container nodejs │
│ Normal Started 5s kubelet Started container nodejsAs shown in the events above, the pull time took ~ 26 seconds.
Next, we'll repeat the same steps but this time changing the image property and using the eStargz-optimized one: ghcr.io/stargz-containers/node:13.13.0-esgz
apiVersion: v1
kind: Pod
metadata:
name: nodejs-stargz
spec:
containers:
- name: nodejs-stargz
image: ghcr.io/stargz-containers/node:13.13.0-esgz
command: ["node"]
args:
- -e
- var http = require('http');
http.createServer(function(req, res) {
res.writeHead(200);
res.end('Hello World!\n');
}).listen(80);
ports:
- containerPort: 80Let's apply the Pod spec to the cluster:
kubectl apply -f pod-estargz.yml and watch the events with kubectl describe pod nodejs-stargz:
│ Events: │
│ Type Reason Age From Message │
│ ---- ------ ---- ---- ------- │
│ Normal Scheduled 12s default-scheduler Successfully assigned default/nodejs-stargz to stargz-demo-control-plane │
│ Normal Pulling 11s kubelet Pulling image "ghcr.io/stargz-containers/node:13.13.0-esgz" │
│ Normal Pulled 3s kubelet Successfully pulled image "ghcr.io/stargz-containers/node:13.13.0-esgz" in 8.730993491s │
│ Normal Created 2s kubelet Created container nodejs-stargz │
│ Normal Started 2s kubelet Started container nodejs-stargz │
│As shown in the events above, the pull time took ~ 8 seconds.
Conclusion
So, what I learned is that with eStargz the initial pull operation will take less time as it doesn't need to pull all the layers in the first place. If you're using relatively large images ( > 1 GB) in serverless scenarios, eStargz -optimized images will help you to start up the container faster (while the remaining layers will be requested over the network as they are needed).
If you were to spin up a new container per HTTP request, eStargz would be extremely useful as in our example it will take ~ 8 seconds to create a new replica of the function instead of ~ 26 seconds (69.2% faster!).
Both Kubernetes CronJobs and in Tekton / Argo Workflows would benefit from eStargz-optimized images. For those tools, this could make an entire workflow run much quicker.
Resources
If you want to learn more about eStargz, check out the following resources:
 Kohei Tokunaga
Kohei Tokunaga Kohei Tokunaga
Kohei Tokunaga
https://static.sched.com/hosted_files/kccncna2021/7f/slides.pdf